

Project: The Baby Name Generator
Traversing the Social Security Administration's baby name database

As a newly minted 30 year old, I am entering a new phase in my life. Looking to settle down, put down roots, and some day make my dead grandparents happy by continuing the line.
Having worked with kids for many years, the subject of children’s names was a frequent topic of discussion. A name could be too common (no one wants to be relegated to having their last initial tacked on to their name), it could be too long, it could be too weird—all pitfalls that parents should try their best to avoid when naming their children.
Luckily for us, the Social Security Administration keeps track of the country’s most frequent baby names in a given year, and allows users access to this data:
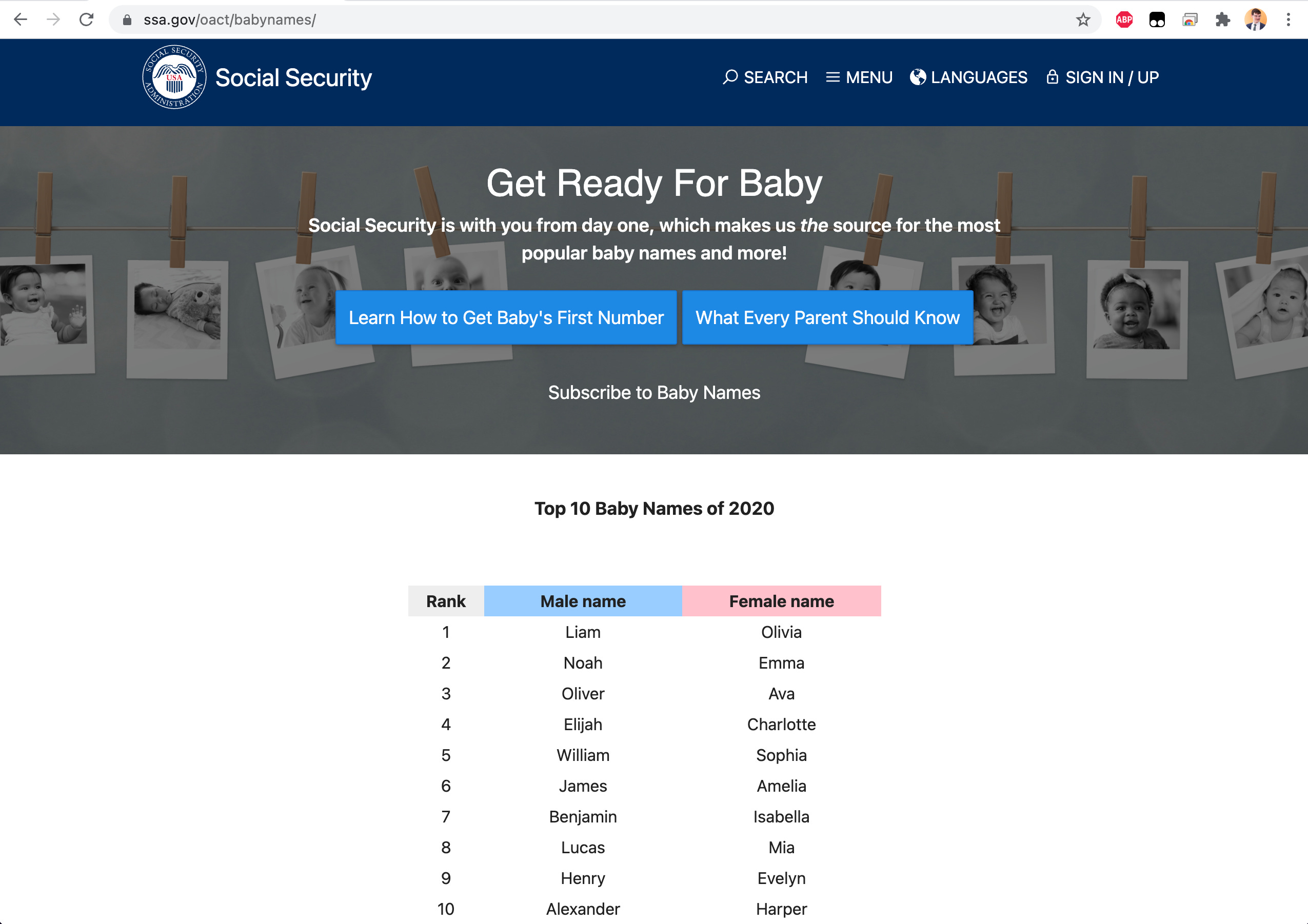
So at the very least, you can avoid the most frequent names from the last few years. So when your daughter Olivia goes on The Bachelor and there’s three other Olivias? That’s on you.
For our “phase 1” project at Flatiron we were assigned to create a single-page application that uses an external database (an “API”) to do something. After some deliberation, my partner and I landed on playing around with the government’s baby name database, as there’s some fun to be had there.
Here’s what we didn’t realize: The federal government is a plodding luddite. There is no organized “API” of the data—when you attempt to download it from the government, they present you with this:


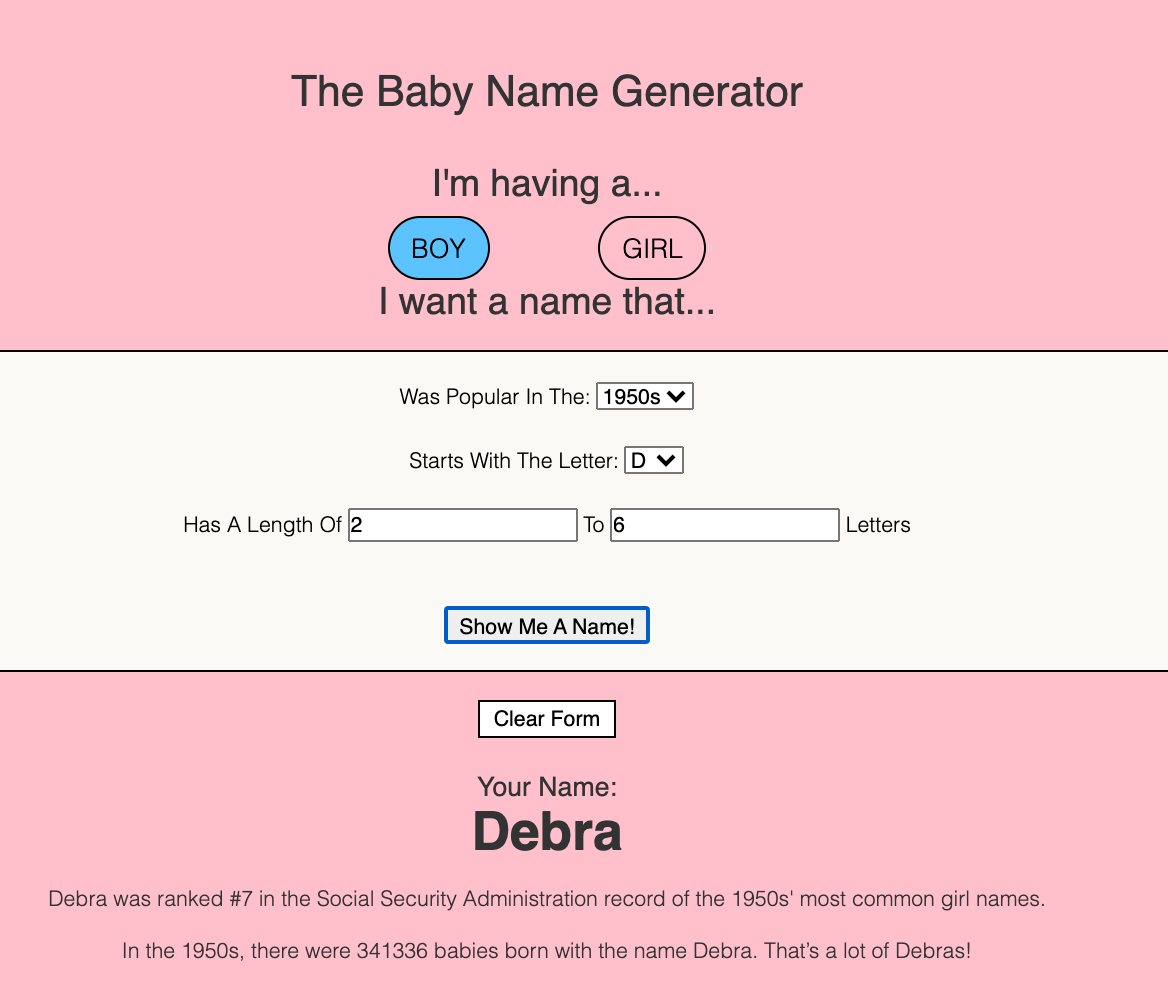
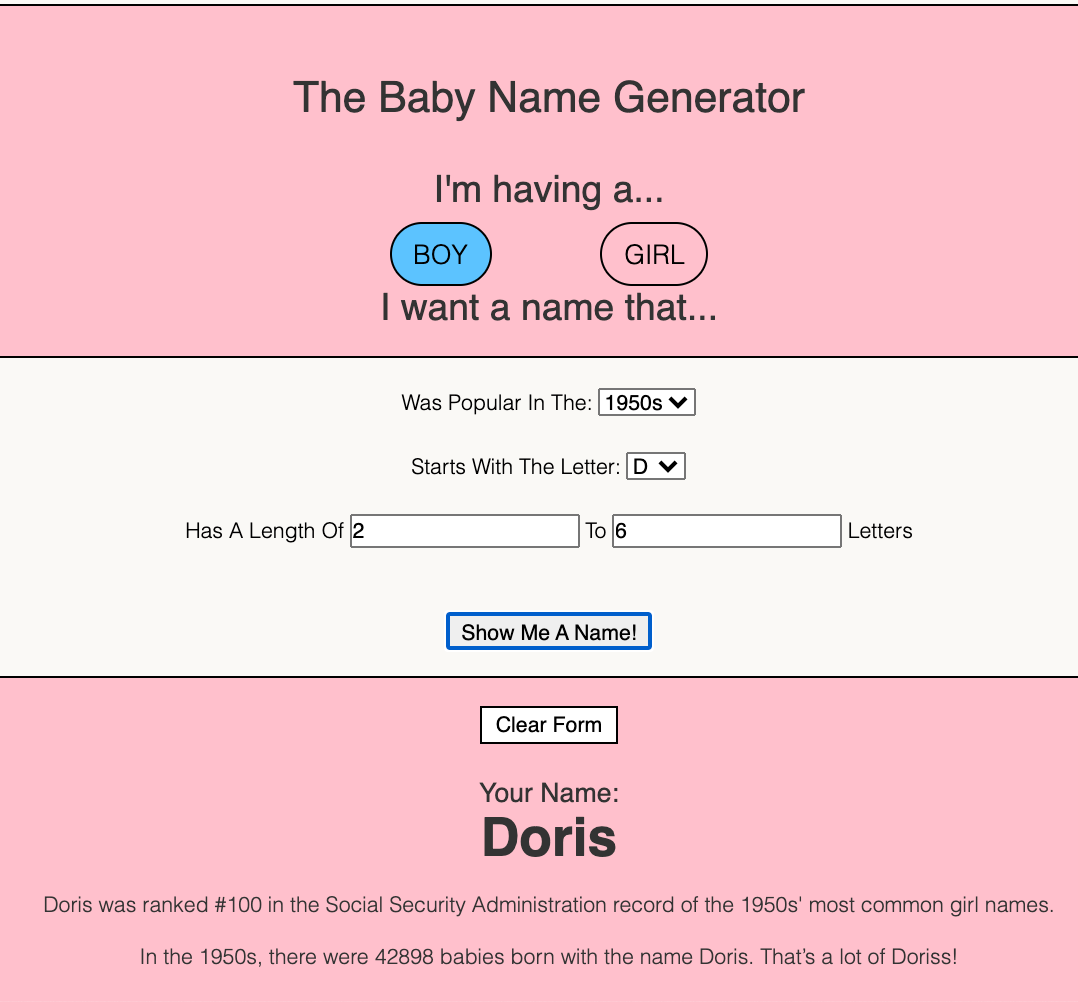
For our project, we landed on a simple “Baby Name Generator.” Users can input some search parameters, (starting letter, desired length, desired time period) and get back a name that fits.

A pretty simple idea, but there was work to be done to make this government data-dump malleable. Before we could get to building a website in Javascript / HTML, which was the actual assignment, there was a lot of work to be done in Python to get this data formatted and uploaded to a server.
Warning: Here’s where things get exciting. But also incredibly dense.



Things were progressing well! We had our data for each year, and through Javascript these sets could be converted to “JSON Objects” to populate an online database.

If you’re sitting there wondering when things were going to get exciting… it’s now.
Some math: You’ll remember I said earlier that each year’s data was anywhere from 2,000-30,000+ lines of text, one line per name. To be exact, for years 1880-2020, we had 2,089,828 lines of text, items of data. And it gets worse:
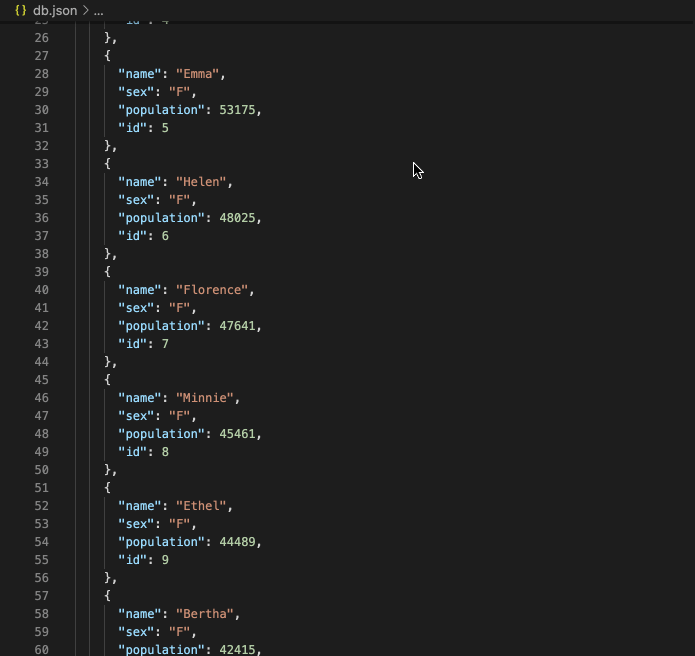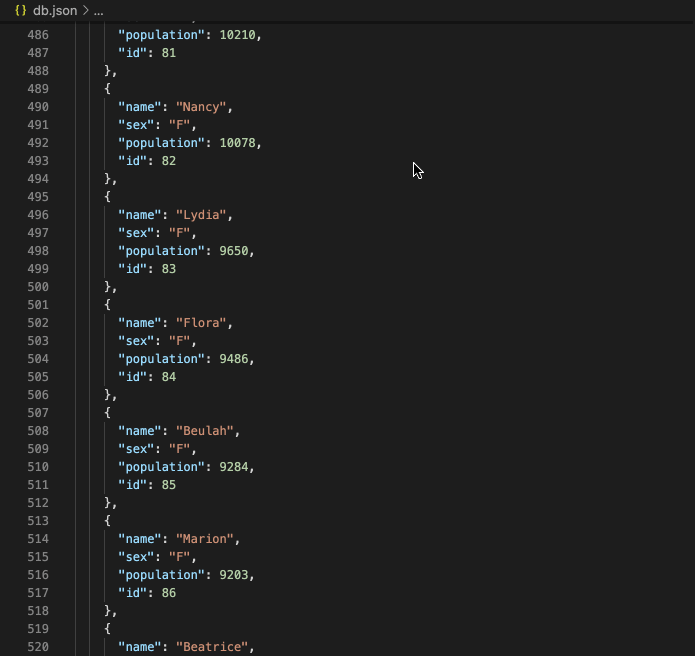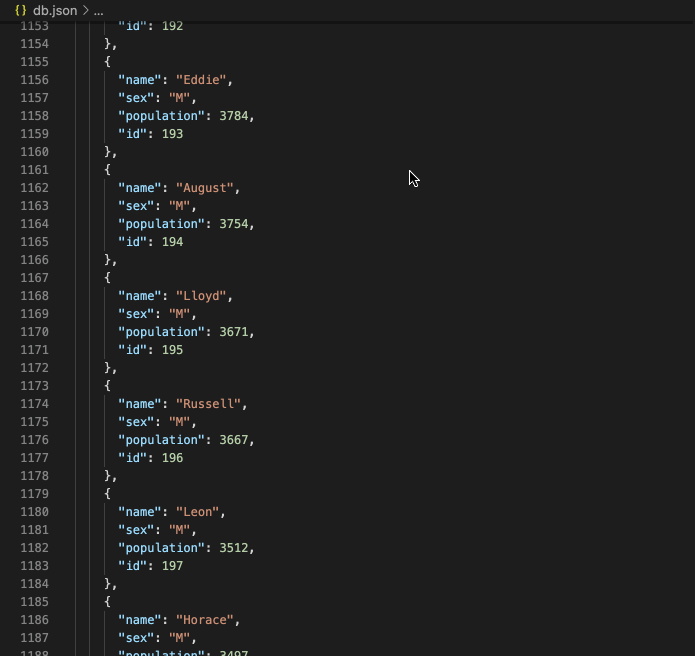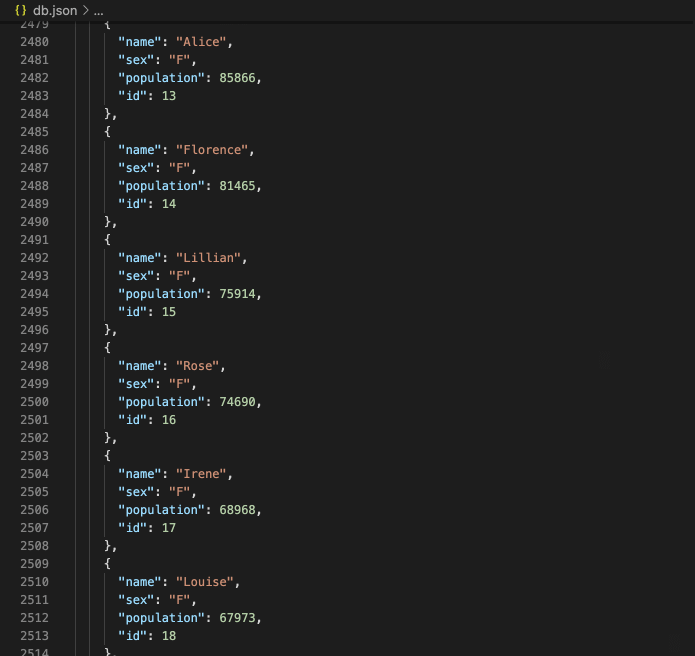
In our text files, a single name, its gender and its popularity together took up one line.
But when uploaded as a JSON object, our one-line-of-text name is now 6 lines of code!
{ // Open bracket { creates new object, 1
"name": "value", // Assigns a Name value to object, 2
"sex": "value", // Assigns a Gender value to object, 3
"popularity": value, // Assigns a Popularity value to object, 4
"id": value // ID is automatically generated by server, 5
}, // } ends object, , sets up the next object, 6
So our 2,089,828 lines of text just became 12,538,698 lines of code. Throw in another 140 lines, one for each year, and this… was not manageable. Any data retrieval we tried, any search result filters we build, would have to iterate through over 12 million lines of code and over 2 million entries. We had to shrink our data set.
We had a few solutions. Our first cut our data load by nearly 9/10ths: Combine the databases for every 10 years, and let users pick their favorite decade instead of a years range.

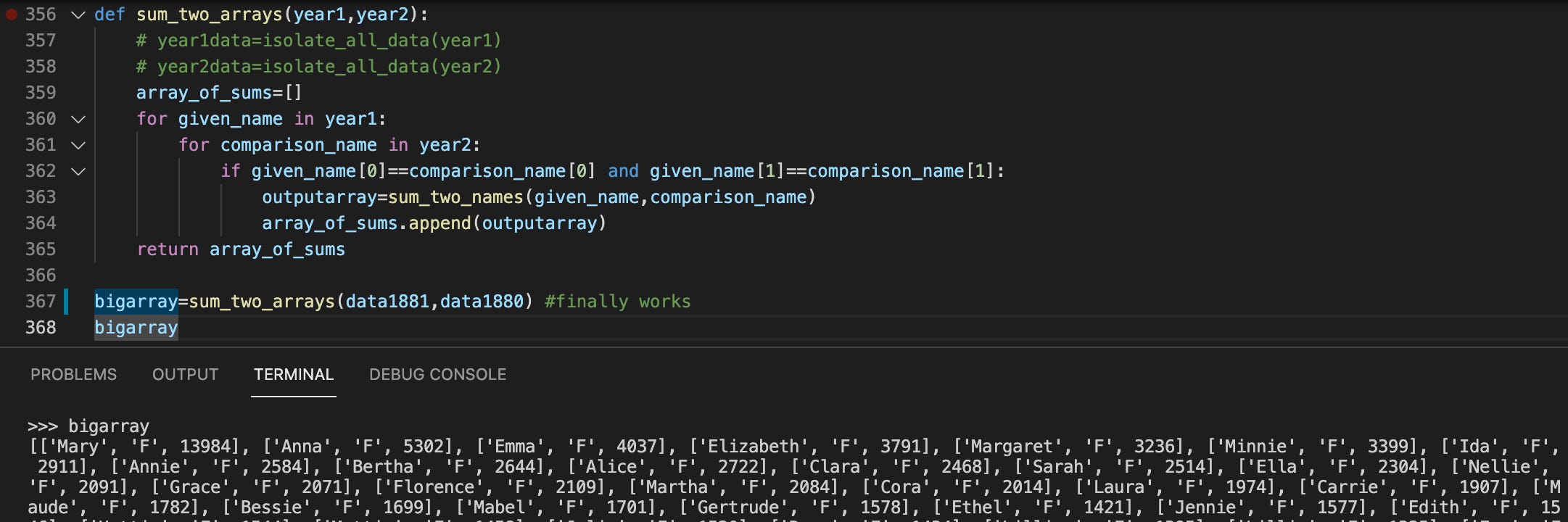
When two years are combined, their data isn’t quite cut in half, but it’s close! Other than a few names that appear on one list and not the other, most names combine with their counterpart, giving us around half the items of data.
But even after combining entire decades, we were still facing if not a mountain of data, quite a large hill. Our next solution was simple: instead of using the entire name database from a given decade, reduce each decade to its top x names, which not only put a hard ceiling on data items but gave us more distinct and flavorful names of the era.
There was some work to be done, but there was a solution in sight, which was a relief after the panic that comes with staring down 12 million lines of code.

From here we could finally produce our database: we chose our cutoff point as the top 100 names of each decade, first, an aesthetically pleasing number—second, that after starting at 50 names, we felt like each time we went back a few spots the names got more fun and era distinct.
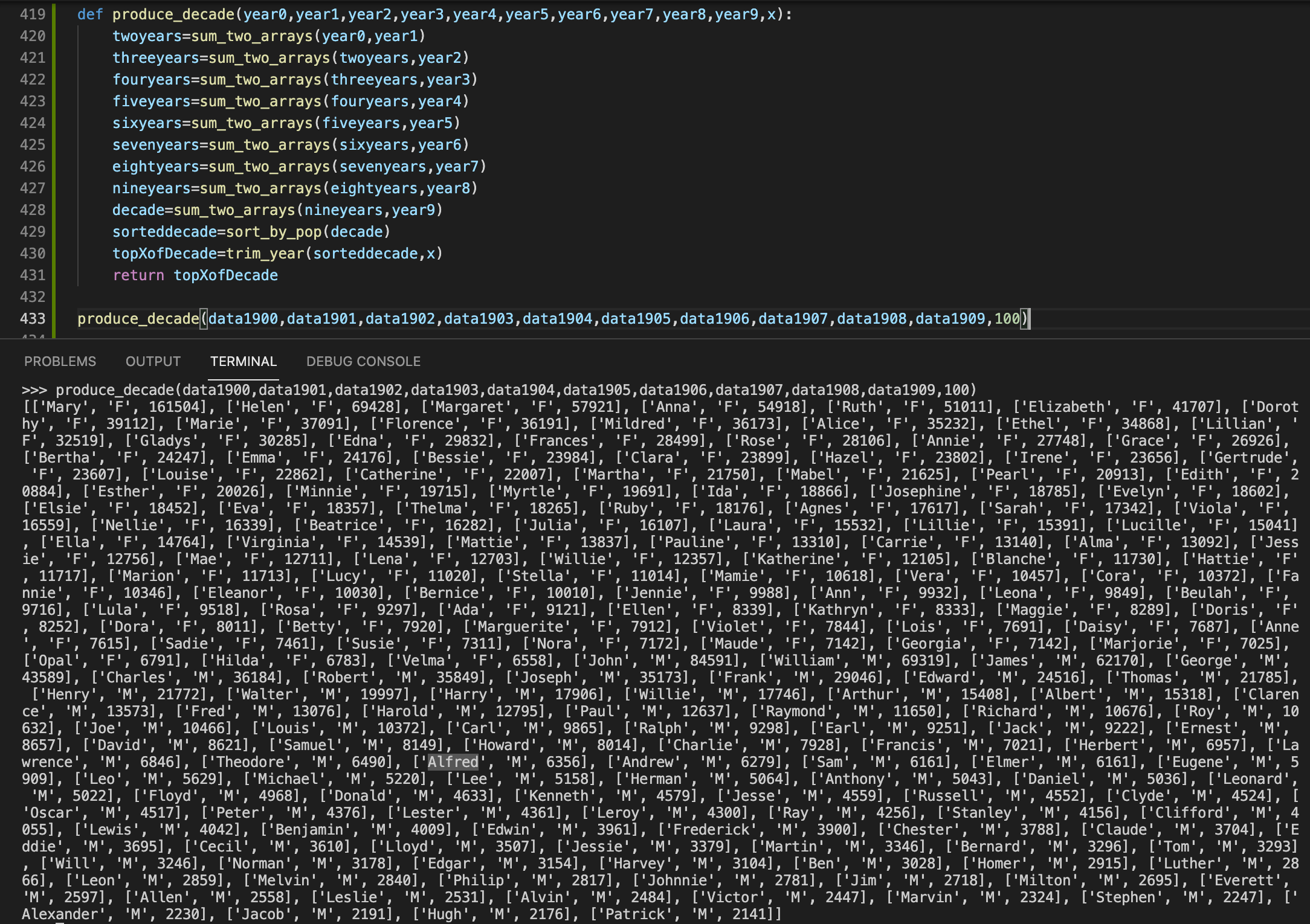
We pushed these new Top 100 of Each Decade datasets to the JSON database, and ended up with a modest 16,824 lines of code. Quite manageable for the modern computer. With the data finally finished, we could work on… actually building the website:

We built filters for users to select between Boy and Girl names, to select a favorite decade, a starting letter preference (or no preference!), and a length preference.

And… it works!


There’s a few more features I’d like to add, that shouldn’t be too many hours of work but weren’t quite ready in time for due date:
Gender neutral name support. The government data may be archaic and regressive, but the name generator doesn’t have to be. Couldn’t quite finish it in time, but it’s almost there:

Filter for recent popularity. Admittedly, something I considered one of the core filters that we just couldn’t get to work in time. One where users can specify if they want a name that’s currently Common, Rare or Very Rare, and names are compared against a database of only the last 5 years.
Actually getting it online so you can play around with it. I’m sorry that I saved that reveal for so late in the post. It’s not online. You can’t use it. It’s technically online on Github Pages but it won’t run because they don’t provide server support. I’m working on it, people!
In the end, I walked away quite happy with the page. It’s a charming little website that’s fun to play around on; it has some genuine utility, and even if doesn’t seem like some technological wonder at first glance—the process of getting it organized, up and running made this project more than meets the eye.
Awesome tool. Will to sure to use when I am naming my children. 1940s names all the way baby ;)!!